하지만 인공지능에서 새로운 가치를 발견하는 것은 그리 간단하지 않다. 인공지능의 미래와 그것이 인류에게 어떤 의미가 될 것인지, 또는 어떤 의미가 돼야 할 것인지에 대해 많은 대화가 오가고 있다. 대부분의 연구자는 인공지능(AI)이 사랑이나 증오와 같은 인간의 감정을 나타내지 않을 것이므로 AI가 의도적으로 선하거나 악해질 이유가 없다는 데 동의하고 있다.
지능정보시스템학회 학회장인 경희대 이경전 교수는“사람을 닮는 인공지능(AI)”의 위험에서 “인공지능은 합리적으로 인간 기능을 수행하는 인공지능”으로 정의돼야 한다고 말한다. 하지만 AI가 위험 요소가 될 수 있는 시나리오들을 고려해봤을 때 전문가들은 가장 가능성이 높은 아래 두 가지 시나리오를 꼽는다.
우선 AI가 치명적인 작업을 하도록 프로그램 되어있는 경우: 예를 들어 자율병기들은 살상하도록 프로그램 되어있는 인공지능 시스템이므로 이 무기의 잘못된 사용은 대량의 사상자를 쉽게 유발할 수 있다. 더욱이 인공지능 무기 경쟁이 우발적으로 AI 전쟁을 초래한다면, 이 무기들은 적들의 방해를 피하고자 임무를 중단하는 것이 극히 어렵도록 설계 될 수도 있으므로, 인간은 그러한 상황을 통제할 수 없게 될 수 있다. 이러한 위험은 제한된 AI의 한해서도 존재하지만 높아지는 AI의 지능과 자율 수준에 따라 증가한다.
또한 인공지능이 유익한 작업을 하도록 프로그램 되어있지만 목표 달성을 위해 임의적(任意的)으로 파괴적인 방법을 사용하는 경우: 이 경우는 인공지능의 목표를 우리의 목표와 완벽하게 일치시키지 못하였을 때 일어날 수 있다. 예를 들어 자율 자동차에게 공항으로 가능한 가장 빨리 데려다줄 것을 요구한다면 우리의 요구가 문자 그대로 받아들여진다면 가장 빨리 주행하는 것에 대한 부작용이 발생할 수 있으며, 그 부작용을 막으려는 인간의 노력이 인공지능에게는 목표 달성에 대한 위협으로 받아들일 수도 있기 때문이다.
인공지능은 그 어떤 인간보다 더 똑똑해질 가능성이 있으므로 인간의 지능으로는 AI가 어떻게 행동할지 예측할 수 있는 확실한 방법이 존재하지 않다. 우리가 고의로 혹은 의도치 않게 우리를 능가할 수 있는 능력을 갖춘 것을 만들어 본 적이 아직 없기 때문에 우리는 과거의 기술을 바탕으로 대처할 수도 없기 때문이다.
본지는 최근 전 세계 인공지능(AI)관련 최신 발표된 논문으로 '딥 컨볼루션 네트워크를 이용한 저조도 이미지 향상' 등 강화학습(1), 신경망(4), 자연어처리(4), 이미지분석(4) 등 최근 공개된 논문 14종을 요약 정리하고 더 자세한 내용은 해당 논문을 바로 볼 수 있는 링크를 연결해 봤다.
제목: 멀티 에이전트 강화학습에 대한 통합 게임의 이론적 접근법(A Unified Game-Theoretic Approach to Multiagent Reinforcement Learning)
저자: 딥마인드- Marc Lanctot, Vinicius Zambaldi, Audrunas Gruslys, Angeliki Lazaridou, Karl Tuyls, Julien Perolat, David Silver, Thore Graepel
요약: 일반적인 정보를 얻으려면 공유 환경에서 다른 사람들과 상호 작용하는 법을 배워야한다. 이것은 멀티 에이전트 강화 학습 (MARL)의 과제이기도 하다. 가장 간단한 형태는 독립적인 강화학습(InRL)으로, 자신의 경험을 비정적 환경의 일부로 간주한다. 이 논문에서 먼저 InRL을 사용하여 학습한 정책이 교육 중에 다른 에이전트의 정책에 아주 적합할 수 있으며, 실행 중에 충분히 일반화되지 못한다는 사실을 관찰한다.
이 효과를 정량화하기 위한 새로운 메트릭스인 공동 정책 상관 관계를 소개한 논문으로 딥 강화 학습을 사용하여 생성된 정책의 혼합에 대한 최상의 반응과 정책 선택을 위한 메타 전략을 계산하기 위한 경험적 게임 이론 분석을 기반으로 일반 MARL에 대한 알고리즘을 설명했다. 알고리즘은 InRL, 반복된 최상의 응답, 이중 예언 및 가상의 재생과 같은 이전의 것을 일반화 한다. 그런 다음 분리된 메타 솔버를 사용하여 메모리 요구 사항을 줄이는 확장 가능한 구현을 제시한다. 마지막으로, 부분적으로 관찰 가능한 두 가지 설정인 그리드 월드 코디네이션 게임과 포커에서 결과의 일반성을 보여준다.(논문 다운받기)

제목: gated-recurrent 신경 네트워크와 같은 피질 미세 회로(Cortical microcircuits as gated-recurrent neural networks)
저자: 옥스포드, 딥마인드- Rui Ponte Costa, Yannis M. Assael, Brendan Shillingford, Nando de Freitas, Tim P. Vogels
요약: 피질 회로는 다른 뇌 영역에서 현저하게 유사하며, 복잡하고 반복적인 구조를 나타낸다. 이러한 고정 관념의 구조는 일반적인 계산 원리의 존재를 시사한다. 그러나, 그러한 원칙은 여전히 애매하다. 장기 메모리 네트워크 (long-term memory networks, LSTMs)에 기반을 둔 게이트 메모리 네트워크(Gated-memory network)에 의해 영감을 받아, 우리는 subtractive(subLSTM)인 저해 세포를 통해 정보가 게이팅되는 반복적인 신경망을 소개한다.
저자는 알려진 정준 흥분 억제 피질 미세 회로에 subLSTM을 자연스럽게 매핑할 것을 제안하고 연속적인 이미지 분류 및 언어 모델링 작업에 대한 경험적 평가는 subLSTM 단위가 LSTM 단위와 유사한 성능을 달성할 수 있음을 보여준다. 이러한 결과는 대뇌 피질 회로가 복잡한 문맥 문제를 해결하도록 최적화 될 수 있고 그 계산 기능에 대한 새로운 관점을 제안한다. 전반적으로 작업은 생물학적 대응물과 함께 기계학습에 사용되는 재발 네트워크를 통합하는 단계를 제공한다. (논문 다운받기)

제목: 충실도 가중 학습(Fidelity-Weighted Learning)
저자: 암스테르담 대학, 구글 브레인 등- Mostafa Dehghani, Arash Mehrjou, Stephan Gouws, Jaap Kamps, Bernhard Schölkopf
요약: 딥 신경 네트워크 훈련에는 많은 훈련 샘플이 필요하지만 실제 훈련 라벨은 신뢰할 수 있는 전문가 라벨러에서 온 것일 수도 있으며, 군중 조달과 같은 약한 감독의 다른 소스에서 오는 것일 수도 있으므로 다양한 품질을 가질 수 있다 . 이것은 학습 과정에서 근본적인 품질 대 수량의 균형을 만든다. 적은 양의 고품질 데이터 또는 잠재적으로 많은 양이 약하게 라벨링 된 데이터를 통해 학습할까?
학습자가 데이터의 표현을 학습할 때 레이블 품질을 어떻게든 알 수 있고 받아들일 수 있다면 두 가지 장점을 모두 얻을 수 있다고 주장한다. 이를 위해 약한 라벨 데이터를 사용하여 딥 신경 네트워크를 학습하는 "충실도 가중 학습"(Fidelity-Weighted Learning, FWL)을 제안goT다. (논문 다운받기)

제목: 온라인 필기 한자 인식을 위한 새로운 하이브리드-파라메트릭 신경망 제어(A New Hybrid-parameter Recurrent Neural Networks for Online Handwritten Chinese Character Recognition)
저자: 중국 과학 아카데미- 하이킹 렌 웨이 치앙 왕
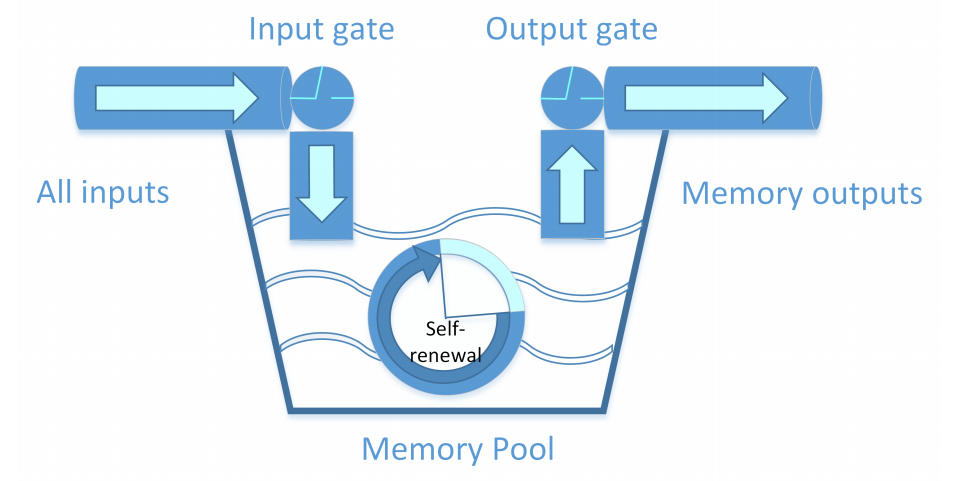
요약: 순환 신경망(RNN, 循環神經網)은 순서를 처리하는데 적합하다. 본 논문에서는 새로운 RNN을 소개하고 온라인 필기 한자 인식에 적용한다. 기존 RNN 모델과 비교하여 제안된 시스템에는 세 가지 혁신이 포함된다. 첫째, 시간 정보를 더 잘 학습하기 위해 RNN을 위한 새로운 숨겨진 계층 함수가 제안된다. 메모리 풀 단위(MPU)라고 부른다. 제안된 MPU는 간단한 아키텍처를 가지고 있다.
둘째, RNN의 발현 용량을 증가시키기 위해 하이브리드 파라미터를 갖는 새로운 RNN 아키텍처가 제시된다. 제안된 복합 매개 변수 RNN은 시간 차원에서 반복을 계산할 때 매개 변수가 변경된다. 셋째, 각 계층의 모든 출력이 네트워크의 출력으로 쌓이는 방식을 적용하며, 누적된 숨겨진 레이어 상태는 표현 용량을 늘리기 위해 모든 숨겨진 레이어 상태를 결합한다. (논문 다운받기)
제목: 딥 네트워크의 압축 인식 교육(Compression-aware Training of Deep Networks)
저자: 도요타연구소Toyota Research Institute) - Jose M. Alvarez, Mathieu Salzmann
요약: 최근 갈수록 더 심화된 신경망의 개발 덕분에 다양한 응용 분야에서 큰 진전이 있다. 네트워크의 엄청난 수의 유닛이 계산적으로나 메모리적으로 비용이 많이 든다. 이를 극복하기 위해 딥 네트워크가 과도하게 매개 변수화되어 있다는 사실을 이용하여 몇 가지 압축 전략이 제안되었다. 그러나 이러한 방법은 일반적으로 앞으로의 압축을 고려하지 않고 표준 방식으로 교육된 네트워크에서 시작된다.
이 논문에서는 훈련 과정에서 압축을 명적으로 설명할 것을 제안했으며, 이를 위해 각 계층의 매개 변수 행렬이 학습 중에 낮은 순위를 갖도록 권장하는 정규 표현식을 도입하는 방법 등 (논문 다운받기)

자연어처리
제목: A4 NT:신경망 기계 번역의 비상 학습에 의한 저작자 특성의 익명성(A4 NT: Author Attribute Anonymity by Adversarial Training of Neural Machine Translation)
저자: 막스 플랑크 인포 매틱스 연구소- Rakshith Shetty, Bernt Schiele, Mario Fritz
요약: 텍스트 기반 분석 방법을 사용하면 성별, 나이 및 텍스트 작성자의 신원과 같은 개인 정보 관련 작성자 속성이 공개될 수 있다. 이러한 방법은 저자가 개인 정보가 민감한 콘텐츠를 제거하려고 할 때에도 저자의 개인 정보를 손상시킬 수 있다. 논문에서는 이러한 텍스트 기반의 대응 위해 Adversearial Author Attribute Anonymity Neural Translation(A4 NT) 이라는 자동 방법을 제안했다.
기계 번역에 사용되는 시퀀스 - 시퀀스 언어 모델과 생성적 적대 네트워크를 결합하여 저자 속성을 난독화하며, 쌍으로 된 데이터가 필요한 기계 번역 기술과는 달리, 서로 다른 저자가 포함된 텍스트의 페어가 되지 않은 부분에 대해 교육을 받을 수 있다. 또 A4 NT 에 제약을 가하는 기술을 제안하고 평가한다. A4 NT입력 텍스트의 의미를 보존하며, A4 NT는 입력 내용의 의미를 유지하면서 저자 속성 분류자를 성공적으로 은폐할 수 있도록 입력 텍스트를 최소한으로 변경하는 법을 학습한다. 제안된 방법으로 저작자 속성 분류자를 속여 저작자의 익명성을 개선하는데 효과적이라는 두 개의 다른 데이터 세트와 셋팅에 대한 것을 실험을 통해 보여준다.(논문 다운받기)
제목: 다중 레이어 네트워크를 이용한 추출 다중 문서 요약(Extractive Multi-document Summarization Using Multilayer Networks)
저자: 상파울로 대학 수학 컴퓨터 학회- Jorge V. Tohalino, Diego R. Amancio
요약: 거대한 양의 텍스트 정보가 매일 생성된다. 이러한 대규모 데이터 세트를 구성하고 이해하기 위해 최근에는 요약 기술이 널리 보급되고 있다. 이런 기술은 큰 데이터에서 관련성이 높고 간결하며, 중복되지 않는 콘텐츠를 찾는데 그 목적으로 하고 있다. 일부 시나리오에서는 텍스트를 모델링하기 위해 네트워크 방법이 채택되었지만 다중 문서의 요약 작업에서 다층 네트워크 모델의 체계적인 평가는 몇 가지 연구로 제한되었다.
여기서는 추출 다중 문서 요약(MDS) 작업의 맥락에서 가장 관련성 높은 문장을 선택하기 위해 다중 계층 기반 방법의 성능을 평가하며, 채택된 모델에서 노드는 문장을 나타내고 가장자리는 문장 사이의 공유 단어의 수를 기반으로 생성된다. 다중 문서 요약은 이전 연구와 달리, 서로 다른 문서(인터 레이어)의 문장과 동일한 문서(인트라 레이어)의 문장을 연결하는 가장자리 사이의 구별을 한다. 원칙의 증거로서, 논문의 결과는 다중 계층 표현에서 내부 및 내부 계층 간의 차별이 생성된 요약이 품질을 향상시킬 수 있음을 보여준다. 이 기술은 현재 통계 방법과 관련 텍스트 모델을 개선하는데 사용될 수 있다.(논문 다운받기)

제목: 개방형 어휘를 이용한 온라인 언어 모델링을 위한 바인딩 되지 않은 캐시 모델(Unbounded cache model for online language modeling with open vocabular)
저자: Facebook AI Research- Edouard Grave, Moustapha Cisse, Armand Joulin
요약: 최근에, 연속 캐시 모델은 반복적인 신경망 언어 모델에 대한 확장으로서 데이터 분포에서의 국부적인 변화에 그들의 예측을 적응시키기 위해 제안되었다. 이 모델은 최대 수천 개의 토큰만 있는 로컬 컨텍스트를 캡처한다. 논문에서는 연속적인 캐시 모델의 확장을 제안하며, 이 모델은 더 큰 맥락으로 확장될 수 있다.
특히 과거에 숨겨진 모든 활성화를 저장하는 대규모 비 매개 변수 메모리 구성 요소를 사용한다. 또한 근사치 최근 근접 검색 및 양자화 알고리즘의 최근 발전을 활용하여 수백만 개의 표현을 효율적으로 검색하면서 동시에 저장한다. 접근 방법이 새로운 배포판에서 사전 훈련된 언어 모델의 혼란을 상당히 개선한다는 것을 보여주는 광범위한 실험을 수행한다.(논문 다운받기)

제목: 해석되지 않은 장면 텍스트 및 아랍어 스크립트 용 비디오 텍스트 인식(Unconstrained Scene Text and Video Text Recognition for Arabic Script)
저자: 인도 시각 정보 기술 센터 등- Mohit Jain , Minesh Mathew , CV Jawahar
요약: 아랍어에 대한 견고한 인식기를 구축하는 것은 항상 어려움을 겪고 있다. 비디오 및 자연 장면에서 아랍어 텍스트를 인식할 수 있는 포괄적인 CNN-RNN 하이브리드 아키텍처의 효과를 입증했으며, 공개적으로 이용 가능한 두 개의 비디오 텍스트 데이터 세트인 ALIF 및 ACTIV에 대해 이전의 기술을 능가한다. 장면 텍스트 인식 작업을 위해 새 아랍어 장면 텍스트 데이터 집합을 소개하고 기준 결과를 설정한다.
아랍어와 같은 스크립트의 경우 견고한 인식기를 개발하는데 있어 중요한 과제는 많은 양의 주석이 달린 데이터가 부족하다는 것으로 논문에서는 아랍어 단어 및 어구의 큰 어휘에서 수백만 아랍어 텍스트 이미지를 종합하여 이 문제를 해결한다. 구현은 영어 장면 텍스트 인식에 매우 효과적인 것으로 입증된 여기에 소개 된 모델위에 구축되었다. 이 모델은 세그먼테이션 프리 (segmentation-free) sequence to transcription approach (시퀀스 전사 접근법). 네트워크는 입력 이미지에서 일련의 대상 레이블로 컨볼루션 특징 시퀀스를 전사한다. 이것은 입력 이미지를 구성 문자 / 글리프로 세분할 필요가 없으며, 이는 아랍어 스크립트에서는 어렵지만 RNN이 문맥 의존성을 모델링 할 수 있는 우수한 인식 결과를 산출한다.(논문 다운받기)
이미지 분석
제목: 딥 러닝 네트워크를 통한 망막의 구조 구성 요소 공개(Revealing structure components of the retina by deep learning networks)
저자: 제7회 CDMA국제 학술회의(연구보고)/청화 대학교 자동화학과 Brain-Inspired Computing 연구 센터- Qi Yan, Zhaofei Yu, Feng Chen, Jian K. Liu
요약: 딥 컨볼루션 신경망(CNN)은 시각적 객체 분류 작업에서 인상적인 성능을 보여준다. 또한 시각 시스템에 기록된 신경 반응의 예측을 위한 유용한 모델이다. 그러나 CNN이 시각적인 연결 회로에 관해 학습하는 것에 대한 명확한 이해는 아직 없다. CNN의 기능을 시각화하여 망막에서부터 시각 피질의 고도의 복잡한 회로로 인해 신경 과학의 토대에 가능한 연결을 얻는 것은 쉽지 않다.
논문에서는 도롱뇽의 간단한 생학적 기록과 전기 생리학적 기록을 가진 단일 망막 신경절 세포에 초점을 맞춤으로써 이 문제를 해결했다. CNN을 화이트 노이즈 이미지로 훈련하고 학습한 콘볼루션 필터가 망막 회로의 생물학적 구성 요소와 유사하다는 것을 알았으며, 이러한 필터로 대표되는 특징은 망막 신경절 세포의 기존 수용 영역의 공간을 도와준다. 이러한 결과는 CNN이 신경 회로의 구조 구성 요소를 나타내는데 사용될 수 있음을 시사한다.(논문 다운받기)

제목: 위험한 상황의 이미지 캡션 및 분류(Image Captioning and Classification of Dangerous Situations)
저자: 영국 헤리엇와트대학교 -Octavio Arriaga, Paul Plöger, Matias Valdenegro-Toro
요약: 현재의 로봇 플랫폼은 다양한 산업에서 인간과 협업하기 위해 사용되고 있다. 이러한 환경에는 화재, 부상자, 자동차 사고 등과 같은 비정상적인 상황을 분류하고 전달할 수 있는 자율 시스템이 필요한 것이다. 일반적으로 인간에게 있을 수 있는 잠재적 위험한 상황 등 논문에서는 하나의 이미지만을 입력으로 사용하여 위험한 상황을 분류하고 설명하는 딥 러닝 아키텍처의 설계 및 구현은 물론 로봇 애플리케이션을 위한 비정상 탐지 데이터 세트를 소개했다. 또 97 %의 분류 정확도와 16.2의 METEOR 점수를 획득했다. (논문 다운받기)

제목: 2 방향 융합네트워크를 이용한 원격 감지 영상의 융합(Remote Sensing Image Fusion Based on Two-stream Fusion Network)
저자: 베이징 대학교, 가상 현실 기술 및 시스템의 국가 핵심 연구실 등 - Xiangyu Liu, Yunhong Wang, Qingjie Liu
요약: 원격 감지 이미지 융합(또는 pan-sharper)은 고해상도(PAN) 이미지 단일 대역 폭(PAN) 이미지 및 공간 분해능 다중 스펙트럼 이미지에서 고해상도 다중 스펙트럼(MS) 이미지를 생성하는 것을 목표로 논문에서는 PAN과 MS영상을 위한 2개의 스트림 입력을 가진 딥 수렴 신경 회로망은 원격 탐지 화상의 공유를 위해 제안된다.
첫째로, PAN과 MS는 PAN및 MS영상의 공간과 스펙트럼 정보를 동시에 나타낼 수 있는 콤팩트한 형상 맵을 형성하기 위해 PAN과 MS영상을 추출한다. 마지막으로, 부호화된 높은 공간 분해능의 MS이미지는 인코딩 부호화 방식을 사용하여 융합된 형상에서 복구된다. Quickbird 위성 영상에 대한 실험은 제안된 방법이 PAN과 MS이미지를 효과적으로 결합할 수 있음을 보여준다.(논문 다운받기)

제목: MSR-net : 딥 컨볼루션 네트워크를 이용한 저조도 이미지 향상(MSR-net : Low-light Image Enhancement Using Deep Convolutional Network)
저자: 중국 후지홍 이공 대학교 영상 인식 및 인공지능연구소 -Liang Shen, Zihan Yue, Fan Feng, Quan Chen, Shihao Liu, Jie Ma
요약: 저조도 상태에서 캡처된 이미지는 대개 매우 낮은 콘트라스트로 인해 컴퓨터 비전 작업의 어려움이 커진다. 논문에서는 Convolutional Neural Network와 Retinex 이론에 기반한 저조도 이미지를 향상시키는 모델을 제안했다. 첫째, 다중 스케일 Retinex는 서로 다른 Gaussian convolution 커널을 가진 피드 포워드 Convolutional Neural Network과 같다.
이 사실에 힘 입어 어둡고 밝은 이미지 간의 종단 간 매핑을 직접 학습하는 컨볼루션 뉴럴 네트워크를 고려했으며, 근본적으로 기존의 접근법과는 달리 이 논문에서는 저조도 이미지 향상은 기계 학습 문제로 간주했다. 이 모델에서 대부분의 매개 변수는 역 전파에 의해 최적화되며, 전통적인 모델의 매개 변수는 인공 설정에 따라 다르다. 다수의 도전적 이미지에 대한 실험은 질적 및 양적 관점에서 다른 최첨단 방법과 비교하여 방법의 특별한 장점을 보여준다.(논문 다운받기)

