
엔비디아(CEO 젠슨 황)가 새로운 엔비디아 텐서RT 3 AI 추론 소프트웨어(NVIDIA® TensorRT 3 AI inference software)를 지난 21일 공개했다.
이번 공개된 소프트웨어는 대폭 향상된 성능을 제공하는 동시에, 자율주행차, 로봇 등과 관련된 클라우드에서 엣지 디바이스에 이르는 추론 비용을 대폭으로 절감할 수 있도록 지원할 것으로 보인다.
특히 공개된 텐서RT 3와 엔비디아의 기존 GPU를 결합하는 경우, 이미지 및 음성 인식, 자연어 처리, 비주얼 검색 및 맞춤 제안 등 인공지능 기반 서비스를 위한 프레임워크 전반에서 초고속으로 효율적인 추론을 구현할 수 있을 것으로 예견된다. 이는 텐서RT와 엔비디아 테슬라 GPU 가속기(NVIDIA Tesla® GPU accelerators)는 CPU 기반 솔루션의 10분의 1에 불과한 비용으로 CPU 대비 최대 40배 가량 빠른 속도를 낼 수 있기 때문이다.
또한 최근 인터넷 기업들은 수십억 인구가 사용하는 서비스에 인공지능을 적용하려는 경쟁에 뛰어들고 있는 가운데 인공지능 추론 작업부하가 기하급수적으로 증가하고 있는 과제를 해결해 나갈 수 있을 것으로 보인다.
이는 발표된 텐서RT는 세계 최초의 프로그래밍이 가능한 추론 가속기로 쿠다(CUDA, Compute Unified Device Architecture)의 프로그래밍 기능과 더불어 텐서RT는 증가 추세에 있는 딥 뉴럴 네트워크의 다양성과 복잡성을 가속화할 수 있기 때문이다. 또한 텐서RT의 놀라운 속도 향상으로 인해 서비스 공급업체들은 연산 집중적인 인공지능 작업부하를 효율적으로 배포할 수 있을 것으로 예상된다.
이미 1,200개(엔비디아 발표자료) 이상의 기업들은 방대한 산업 분야에서 엔비디아의 추론 플랫폼을 이용해 데이터에서 새로운 인사이트를 발견하고, 기업 및 소비자를 대상으로 지능형 서비스를 배포하기 시작했다. 대표적인 기업으로는 아마존, 마이크로소프트, 페이스북, 구글이 있으며, 중국의 주요 대기업인 알리바바, 바이두, JD.com, iFLYTEK, 하이크비전, 텐센트, 위챗 등도 포함된다.
요약해보면, 테슬라 GPU상에서 텐서RT 소프트웨어를 활용하는 엔비디아의 AI 플랫폼은 추론 기능의 필수요건을 수행하는 데 있어 가장 최근의 탁월한 기술로 텐서RT와 엔비디아 GPU는 고객의 니즈를 충족하기에 충분한 최대의 머신러닝 성능과 범용성에 기반하여 실시간 서비스 구현을 가능케 할 것으로 보인다.
또한 현재 많은 글로벌 기업들의 데이터센터의 추론 기능을 활용하기 위해 엔비디아 GPU와 소프트웨어에 의존하고 있다. 곧 테슬라 GPU상에서 엔비디아의 발표자료에 의하면 이번 텐서RT를 사용하면 20분의 1의 서버만으로 1,000개의 HD 동영상 스트림을 실시간으로 일제히 추론할 수 있는 것이다.
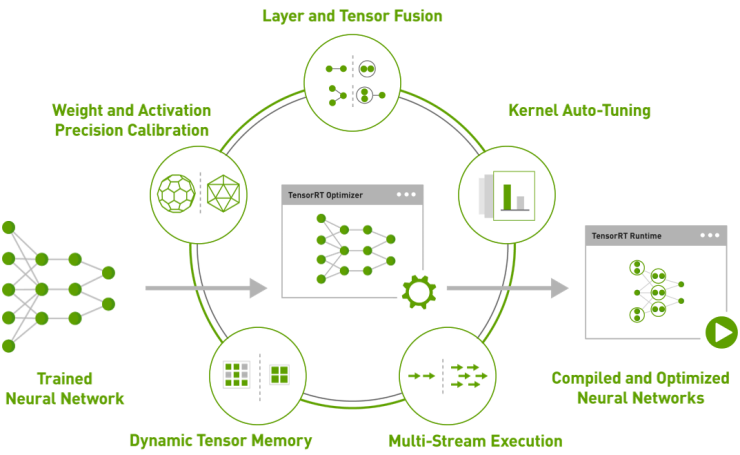
아울러 텐서RT 3는 AI 애플리케이션의 생산 및 배포를 위한 고성능의 최적화 컴파일러 및 런타임 엔진으로, 트레이닝을 거친 추론용 뉴럴 네트워크를 하이퍼스케일 데이터센터, 임베디드 또는 차량용 GPU 플랫폼으로 최적화, 승인 및 배포하는 작업을 신속하게 진행할 수 있다.
마지막으로, 텐서RT 3는 INT8(8비트 정수) 및 FP16(16비트 반정밀도 부동소수점) 연산의 네트워크 실행에서 높은 정확도를 보이며, 데이터센터 운영업체는 매입비용 및 연간 에너지 비용을 수천만 달러 가량 절감할 수 있을 것으로 예상되며, 개발업체의 경우는 텐서RT 3를 사용하면 트레이닝을 거친 뉴럴 네트워크(신경망, neural network)를 이용해 단 하루 만에 배포 가능한 추론 솔루션을 형성할 수 있으며, 해당 솔루션은 트레이닝 프레임워크 대비 3배에서 5배 가량 빠르게 작동하는 것으로 보인다.
참고) 아래는 인공지능 가속화를 촉진하기 위해 엔비디아는 텐서RT 3외 아래와 같은 추가적인 소프트웨어를 동시에 공개했으며, 이번에 공개된 관련 소프트웨어를 요약해 봤다.
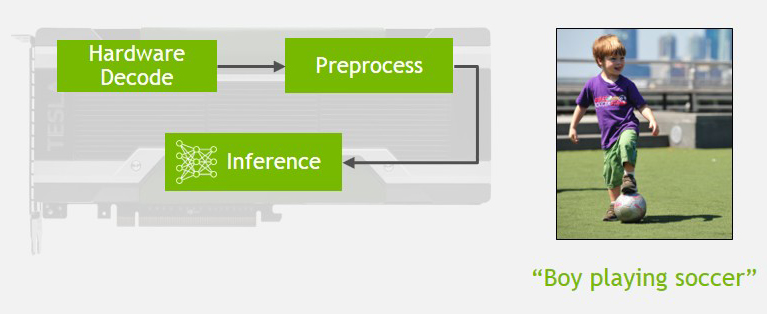
딥스트림 SDK(DeepStream SDK): 엔비디아 딥스트림 SDK(NVIDIA DeepStream SDK는 규모에 관계 없이 실시간으로 저지연(low-latency) 동영상 분석을 제공한다. 이를 통해 개발자들은 INT8 정밀 연산 및 GPU 가속 트랜스코딩 등 첨단 동영상 추론 기능을 통합, 단 하나의 테슬라 P4 GPU 가속기(Tesla P4 GPU accelerator)에서 최대 30개의 HD 스트림에 대해 사물 분류 및 장면 이해 등 인공지능 기반 서비스를 실시간으로 지원할 수 있다.
쿠다 9(CUDA 9): 엔비디아의 가속 컴퓨팅 소프트웨어 플랫폼인 CUDA®의 최신 버전으로, HPC 및 딥 러닝 애플리케이션의 속도 향상과 더불어 엔비디아 볼타(NVIDIA Volta) 아키텍처 기반 GPU 지원, 최대 5배 빠른 라이브러리,스레드 관리를 위한 신규 프로그래밍 모델 및 디버깅과 프로파일링 도구에 대한 업데이트를 제공한다. CUDA 9는 테슬라 V100 GPU(Tesla V100 GPU) 가속기에서 최대의 성능을 구현하도록 최적화되어 있다.
데이터센터용 추론 기능
데이터센터 관리자들은 서버의 생산성을 최대로 유지하기 위해 계속해서 성능과 효율성 사이의 균형을 맞춘다. 테슬라 GPU 가속기는 딥 러닝 추론 애플리케이션 및 서비스를 위한 범용 CPU 서버 수십 대를 대체할 수 있어 랙 공간 문제를 해소할 수 있고, 에너지 및 냉각 관련 필수요건을 줄일 수 있으며 비용을 최대 90% 가량 절감할 수 있다.
엔비디아 테슬라 GPU 가속기는 최적의 추론 솔루션을 제공한다. 본 솔루션은 딥 러닝 추론 작업부하의 처리에 있어 최대 처리량, 최고의 효율성 및 최저수준의 지연성이 결합되어 있어 새로운 인공지능 기반 경험을 제공하기에 충분하다.
자율주행 차량 및 임베디드 애플리케이션용 추론 기능
엔비디아의 통일된 아키텍처 덕분에 딥 러닝 프레임워크의 종류에 관계 없이 데이터센터 내 엔비디아 DGX(NVIDIA DGX™) 시스템에서 딥 뉴럴 네트워크를 트레이닝할 수 있으며, 로봇부터 자율주행 차량에 이르기까지 모든 종류의 디바이스에 배포해 엣지에서의 실시간 추론을 실현할 수 있다.
