사회와 산업이 스마트시대로 돌입하고 있다. 동시에 데이터 양(量) 또한 방대해 지면서 ‘정보의 홍수’라는 말이 무색할 정도로 예측 불허의 빠른 속도로 엄청난 양으로 쏟아지고 있다.
대부분의 공공기관, 기업들은 이처럼 넘쳐 나는 정보를 관리하기 위해 스토리지와 서버, 네트워크, 스위치 등 값비싼 장비나 시스템에 치중하고 있다. 결과적으로 서로 다른 기종을 다양한 환경에서 사용한다. 하지만 이를 분석하고 통합 관리하기 위해 상당한 어려움과 경제적으로도 큰 손실을 초래하고 있다.
우리 기업과 기관들에 ‘데이터경제의 시대!’가 도래한 것이다. 이처럼 넘치는 데이터에 정확한 분석과 효율적인 관리를 위해서는 취급방식에 혁신이 필요한 시점인 것이다.
이에 서울대학교 융합과학기술대학원 디지털정보융합학과 겸임부교수 및 서울대학교 차세대융합기술연구원 링크드(Linked) 데이터센터장 조명대 교수를 통해 데이터경제가 무엇이고 왜 Google Refine(정제)’ 툴을 활용해 데이터 정제를 해야 하고 구체적으로 어떻게 할 것인가에 대한 방법을 인터뷰를 통해 알아본다.

Q. 데이터 '경제'와 데이터 '정제'의 의미는, 또 왜 이들이 필요한지?
A. 우선 데이터 경제부터 설명하자면 데이터 경제는 데이터가 경제활동의 주요한 부분이 되는 경제구조를 말한다. 이미 우리는 데이터가 중심이 되는 새로운 시대를 살고 있다.
기계, 사람 및 조직체에서 데이터를 끊임없이 쏟아내고 있다. 그 데이터를 기반으로 새로운 서비스를 구축하면서 새로운 사업 기회를 찾아가는 세상이 이미 열리고 있다는 것이다.
작금의 빅테이터 분석도 그 중요한 한 축이 될 것이다. 축적된 원시데이터(raw data)위에 계속 가치사슬을 형성해 나가면서 점점 더 새로운 가치를 더해 가기위한 환경이 만들어져 근본적으로 경제구조에 변혁을 가하는 경제를 데이터 경제라고 할 수 있다. 여기서는 가치사슬 중심으로 데이터경제를 논의하고자 한다.
Q,. 앞서 언급한 ‘가치 사슬’이란 무엇을 의미하는가?
A. 데이터 경제에서는 데이터가 가치사슬(Value Chain)처럼 엮어져 있어야 효율성이 높아진다. 그냥 데이터가 우후죽순처럼 생겨난다고 해서 데이터 경제가 이뤄지는 것은 아니다. 자칫 잘 못하면 더 독이 될 수도 있기 때문이다.
원시데이터 단에서는 그 데이터 자체는 별의미가 없이 여기 저기 있지만 이것을 사용하는 목적에 따라 새롭게 재조합해 그 데이터를 분석해 나가면 점점 가치를 띠게 돼 ‘정보’가 되고 또 더 가치를 더해나가면 더 유의미한 ‘지식’으로 변하게 된다.
계속 가치가 부가돼 어떤 의사결정의 귀중한 자료로 사용되는 지식의 단계에까지 올라갈 수 있다는 의미다. 이것은 마치 우리 몸이 단백질인 물질적로만 존재하고 있으나 이것에 뼈와 살이 더해지고 이윽고는 뇌세포까지 조직되는데 활용돼 완전히 다른 상태로 변하는 것과 마찬가지다. 눈에 보이고 만져지던 물리적인 실체가 완전 눈에 보이지 않는 정신적인 실체로 바뀌어 지는 것과 별 다름이 없다.
다시말해 데이터를 필요에 따라 그 데이터 조직을 위한 다양한 행위들의 사슬이 만들어져 계속 가치를 더해가면서 데이터를 점점 더 풍부하게 표현할 수 있게 돼 처음에 기대했던 가치를 추구해 나가는 일련의 행위들에 대한 연속체가 되는 것이다. 데이터가 아주 주요한 원료인 셈이다.
Q. 가치사슬과 관련된 예를 하나 든다면?
A. 이러한 데이터의 경제에서는 필요하다면 다른 서비스 제공자들이 기꺼이 돈으로 지불도 하게 된다. 이른바 ‘데이터 거래’가 자연스럽게 일어나면서 다양한 경제주체들이 아주 자연스럽게 서로의 가진 것을 나누면서 새로운 이익을 추구한다. 이 데이터 경제의 한 형태로 연결경제를 들 수 있을 것이다. 계속 연결이 되면서 가치사슬이 형성된다고 다시 요약할 수 있다.
가령, 기업 등에서 자기의 ‘고객들이 생각하는 가치’를 상상해 그것을 눈에 보이는 형태의 서비스로 만들 필요가 있을 것이다. 아주 중요한 기업 행위다.
지금 IT산업에서 앞서 나가는 기업들이 바로 이런 행위들을 잘해나간다고 볼 수 있다. 그 고객이 생각하는 가치가 데이터를 기반으로 하는 것이라면 더욱더 그러할 것이다. 바로 그 ‘고객들이 생각하는 가치’가 기업자체에서 생산하는 데이터로 충분하다면 남이 만든 데이터가 필요없겠지만 실제 대부분의 경우에는 직접 필요한 데이터를 직접 생산하는 것보다 이미 만들어져 있는 것을 가져와 사용하는 것이 훨씬 효율적인 경우가 많다. 이제 데이터 가치사슬의 예를 들어 보겠다.(그림1 참조)
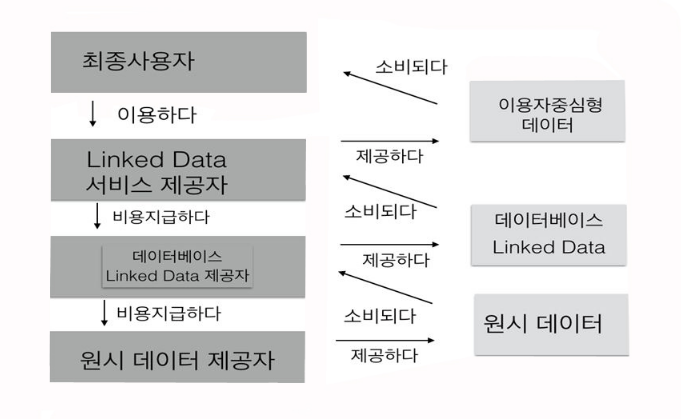
데이터 가치사슬은 4가지의 역할과 3가지의 데이터 형태를 생각해 볼 수 있다. 가치사슬이 형성되고 또 역으로 비용도 지급되고 있음을 알 수 있다. 구체적으로 살펴보면 우선 편리상 4종류의 데이터 제공자 또는 이해당사자로 나눠 보자. 4가지 설명후 제일 마지막에는 제기 될 수 있는 문제점 하나를 지적하겠다.
원시 데이터 제공자 = 먼저 ‘원시 데이터 제공자’다. 현재는 정부3.0 시책에 맞춰 정부의 각 기관에서 다양한 형태로 '있는 그 대로의 원광석 같은 원시자료’를 제공하고 있는 것이 그 구체적인 예가 될 수 있다.
그러나 이제는 꼭 정부기관이 아니더라도 개인 또는 회사가 정부에서 가령, 액셀시트로 발행한 각 시도의 CCTV의 위치 정보를 다시 한 시트로 재가공해 새로운 액셀시트로 만들어 올리면 또 다른 형태의 원시자료가 될 수 있을 것이다.
이때 원시자료 형태는 주로 액셀 등의 스프레드시트(Spreadsheet)가 되겠지만 현재 정부3.0에서는 오픈API로도 많이 내보내고 있다.
데이터베이스 및 Linked Data 제공자 = 데이터베이스 및 Linked Data 제공자는 자신이 가지고 있는 Raw Data 또는 남들이 올린 Raw Data를 활용해 데이터베이스로 만들거나 또는 아래 단에서 제공된 Raw Data를 활용해 RDF 형태의 Linked Data로 발행하는 사업자들이 있을 수 있다.
우리나라에서는 아직 많지는 않지만 정부 프로젝트 기반으로 Linked Data 형태로 발행된 것들이 제법있다. 아주 좋은 시도다.
Linked Data 제공자는 다양한 포맷(예들 들어 xml, html, rdf 및 json 등으로)을 제공해 그 다음 단계인 Linked Data 서비스 제공자들이 활용할 수 있도록 해줘야 한다. 문제는 아직 이런 Linked Data에 가치를 더해 다음 단계인 Linked Data 서비스 단계에 이르지 못한 것이 아직은 아쉬운 단계다.
또한 Linked Data로 제공할 때는 몇 가지 꼭 지켜야 하는 기술(dereferenceable URIs, a SPARQL endpoint or an RDF dump)을 숙지해야 하는 약간의 어려움은 있다. 그러나 이 부분의 종사들에게는 크게 어려움은 없을 것이다.
더 나은 데이터 생태계 조성을 위해서는 더 많은 개인 또는 사업자들이 각 분야별로 질 좋은 Linked Data를 많이 발행해주면 바로 다음단인 서비스 제공자들에 의해 데이터는 점점 더 풍부하게 표현돼 가치 사슬을 형성해 나갈 수 있을 것이다.
이때 Linked Data 제공자들이 제공하는 자료는 주로 RDF 형태다. 현재의 웹에는 없는 기계가 이해할 수 있는 형태의 메타데이터로 바꿔 내보낸다. 주로 RDF/XML 이나 JSON/JSONLD 형태로 내보낸다.
서비스 제공자(Service Provider) = 서비스 제공자는 2가지로 나눠 생각해 볼 수 있다. 먼저 일반 데이터베이스 서비스 제공자들이다. 이들은 Raw Data를 활용한 기존 DB서비스 제공자로서 지금 수많은 앱 제공자들이 여기에 해당된다. 아직은 제일 첫 단이 Raw Data 제공자들의 데이터를 활용하지 않고 스스로 데이터를 가공해 DB서비스를 하는 사업자들이 많다. 지금 대부분의 앱 서비스 제공자들이 이에 해당한다고 볼 수 있다.
또 다른 형태로 Linked Data 서비스 제공자가 나올 수 있을 것이다. 이들은 자기들이 직접 만든 데이터나 원시데이터 제공자나 아니면 Linked Data로 만들어진 데이터를 활용해 이용자에게 직접 서비스를 하는 사업자들입이. 실제 이 서비스 제공자들이 양질의 서비스를 제공해줄 때 최종 이용자들은 자기들이 미처 상상도 못한 서비스를 받게 될 것이다.
앞서 언급한 내용 중 후자의 서비스 제공자들이 많아져야 데이터 경제가 잘 돌아갈 것이다. 스스로 만들어서 서비스하는 업체도 있으나 데이터를 재가공해 사용하는 구조로는 아직 많이 부족한 형편이다.
최종 사용자 = 이 가치사슬의 제일 큰 수혜자는 최종 사용자다. 이들의 요구 사항에 맞춰 그 결과를 일목요연한 콘텐츠 형태로 도출해야 한다. 그들이 ‘생각하는 가치’를 미리 예측을 하고 그들의 눈앞에 만들어내 수익을 창출해야 한다.
이들에게 필요한 형태의 서비스를 제공하기 위해 데이터가 앞서 언급한 단계를 거치면서 때로는 비용을 지급하면서 점점 더 풍부하게 표현된 것이다. 바로 이 마지막 이용자들이 제공된 서비스를 이용해줄 때 사실 경제라는 개념이 빛나게 된다. 지금 구글이나 페이스북 등이 내는 엄청난 경제효과도 바로 이러한 것이다.
그러나 문제는 아직 이런 Linked Data에 가치를 더해 다음단계인 Linked Data 서비스단계에 이르지 못한 것이 아직은 아쉬운 단계이다.
Q. 그렇다면 위에서 언급한 ‘플랫폼’이란 무엇을 의미하나?
A. 이렇게 타인이 제공한 데이터도 즉석에서 자기 서비스에서 활용되게 할 수 있는 구조로 돼야 한다. 즉 그러한 플랫폼이 필요하다는 의미다. 남이 만든 것 및 내가 만든 것도 남이 사용할 수 있게 해주는 운동장이 필요한 것이다. 이때 무엇보다도 중요한 것은 데이터의 품질이다.
"플랫폼이란 서비스가 만들어 지는 재료나 환경을 제공해주면 그것들 위에서 다양한 이용자들이 상호작용을 통해 수많은 가치를 생성해 낼 수 있게 해주는 공간을 말한다."
"이러한 기반과 틀을 마련해주는 곳이 바로 플랫폼이다. 이용자들이 이것을 이용해 맘대로 하고 싶은 대로 하라는 것이다. 그런 환경을 제공해주자는 것이다. 아마 가장 재미있는 현상 중 하나는 이렇게 틀을 제공해주면 사람들이 몰려들어 그 도구를 활용, 무엇인가 새로운 가치를 제공하는 멋진 것을 만들어 낸다는 점이다."
Q. 정부 3.0 일환인 ‘data.go.kr’ 등에서 양질의 데이터를 제공하고 또 다른 개발자들이 사용하고 있지 않나? 바로 그런 것도 플랫폼이 아닌가?
A. 그 것은 플랫폼이라기보다는 그들이 말하는 포털일 것이다. 스스로 공공데이터포털이라고 말하고 있다. 엄청나게 많은 질 좋은 데이터를 개방하고 또 많은 개발자들이 이것을 이용해 앞서 언급한 서비스 제공자가 된 것은 아주 좋은 일이고 칭찬할 만한 일이다.
그러나 앞서 설명한 플랫폼은 아니라는 것이다. 다양한 층의 이용자들이 서로 상호작용을 하면서 점점 더 가치를 더해가는 구조가 아니라는 것이다.
모든 것을 다 진열해 놓은 백화점식 Raw Data도 중요할 수 있지만 진정하게 데이터의 가치사슬을 형성하려면 반듯이 어느 한 분야에 집중하여 소비자와 생산자 사이에 중간층을 하나 더 만들어 수많은 데이터와 그 관련성을 한 눈에 보기 쉽게 제시해줄 수도 있어야 한다.(그림2 참조)
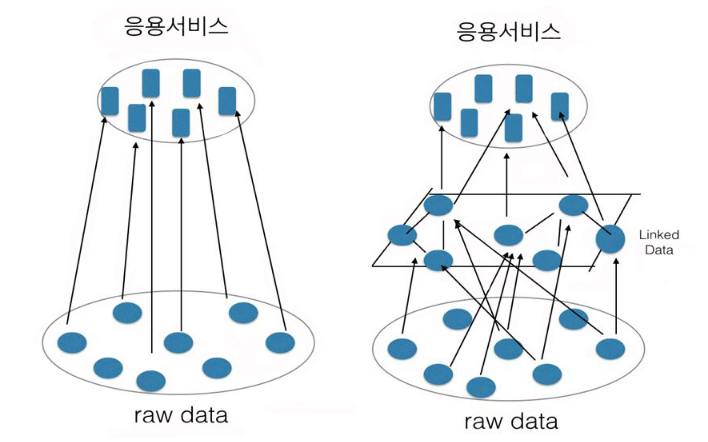
[그림2] 와 같이 좌측은 지금의 데이터포털의 구조며 우측은 ‘어느 한 영역(domain)’에 집중해 데이터의 가치를 서로 높여가는 구조다. 중간에 또 하나의 눈에 보이지 않는 데이터 층이 그래프 구조로 만들어져 있는 것이다.
그렇게 하기 위해서 Linked Data 형태로 발행한다해도 크게 효과를 못 보고 있는 이유중의 하나가 어느 한 영역에 집중해 데이터 상호간에 가치사슬을 형성하지 못한다는 점이다.
이렇게 돼 버리면 Linked Data 본연의 가치를 잃어버리게 된다. 이것은 마치 문제를 해결하겠다고 자신 있게 나섰지만 결국에는 그 자체가 문제의 한 부분으로 환원돼 나가는 것과 비슷하다. 남이 만든 데이터를 잘 이해할 수 있는 해당분야의 전문가들이 남이 한 것 위에 자기가 또 다른 가치를 더할 수 있는(add-on) 그런 영역을 선택해 집중하는 것이 필요하다.
가치사슬이 데이터 그 자체로서 끝이 나버렸다는 것이다. 이렇게 돼서는 안된다. 이 데이터를 이용자들에게 유익하고 그들이 바로 직관적으로 활용할 수 있는 지식그래프를 활용한 서비스단을 구성해줘야 한다. 바로 이런 영역별 지식그래프의 등장은 IT산업에 엄청난 혁신을 안겨다 줄 것이다. 현재 우리에게 이런 서비스가 거의 없다.
또 하나 중요한 사실은 이렇게 한 영역에 집중을 할 때 이 과정에 사용됐던 모든 데이터 (raw data에서 rdf data까지)가 항상 바로 사용될 수 있게 연결돼 있어야 한다는 것이다.
물론 흩어져서 서로 언급될 수도 있겠지만 중앙에 집중적으로 모여 항상 서로 참조될 수 있는 구조가 바람직하다. 이 플랫폼안의 서로 다른 데이터셋을 섞어 또 다른 데이터셋을 만들어 낼 경우가 많기 때문이다.
이러한 것을 ‘데이터 매쉬업’이라고 한다. 영국의 가디언지에 보면 기자들이 이와 같은 매쉬업을 많이 사용한다. 지역별 비만도와 지역별 소득수준을 모아 또 새롭게 가치 있는 정보를 만들어 신문 기사로 활용한다.
각 데이터 셋으로 따로 있을 때는 몰랐는데, 둘은 지역이라는 공동변수 위에 놓고 분석해보니, 가령, '축구가 인기있는 맨체스터지역의 비만도가 높더라'라는 결론이 나올 수가 있을 것이다. 문제는 이렇게 새롭게 만들어진 데이터도 그냥 한번만 이용되고 사라지게 하지 말고, 또 다른 각도로도 계속 활용될 수 있게 해야된다.
그러면 이 데이터는 다시 재활용돼 또 다른 사람이 rdf로 바꿔 영국의 지역별 비만도, 소득수준, 날씨, 공중화장실위치, 병원 분포 등을 표현하는 앱 등에 사용될 수 있을 것이다.
이때 주로 API를 활용해 필요한 데이터를 가져간다. 바로 이 API를 활용해 데이터와 서비스를 좀 더 효율적으로 보호하면서도 새로운 기회를 창출해 내는 창구로 활용한다. 이에 대한 관리가 필요하기 때문에도 더 어느 하나의 큰 서버에 집중돼 있는 것이 효율적이라 할 수 있다.
이 API를 통해 IT 인프라의 효율성 있는 통합과 보안을 추구하고 파트너 및 개발자를 아우르는 생태계의 구축과 조직 내 축적된 데이터의 개방을 통한 수익창출이라는 이득을 실현 할 수 있을 것이다.
데이터가 계속 연결되면 그 가치가 증가한다는 네트워크 효과를 십분 발휘할 수 있는 곳이 바로 이 플랫폼이다. 또 바로 이런 플랫폼의 구축이 바로 데이터경제의 핵심이며 바로 이런 데이터경제가 구축돼 나갈 때 창조경제도 그 빛을 발휘할 수 있을 것이다.
Q. 마지막으로..
A. 데이터 경제에서는 데이터의 활용이 다른 산업 발전의 촉매역할을 할 수 있다. 우리나라 특유의 데이터 활용 생태계를 만들어 창조적 데이터 경제 시대를 앞서가야 할 때다. 이때 활용되는 데이터의 품질이 무엇보다 중요하다.
하지만 현재 존재하고 있는 데이터에는 많은 잡음(noise)이 존재하는 것도 사실이다. 우선 데이터를 깔끔하게 정리해야 데이터베이스를 만들든지 Linked Data형태의 Database를 만들든지 해애 할 것이다. 그 것이 곧 데이터경제의 시대의 우리의 비전이자 미래인 것이다.
